So do not worry about tomorrow, for tomorrow will bring worries of its own. Today's trouble is enough for today. (MATTHEW 6:34)
字符编码
其实,标题前面应该加两个字——“坑爹”。
在实践中,字符编码的确是一个“坑”。因为这个世界上,不都是英文。如果都是英文,就没有这个问题了。可是,还有中文、日文等等。
但是,字符编码的确很重要,它不仅仅是计算机的一个基础,还是一个有历史过程的事情。
要从编码开始谈起。
编码
什么是编码?这是一个比较玄乎的问题。也不好下一个普通定义。我看到有的教材中有定义,不敢说他的定义不对,至少可以说不容易理解。
古代打仗,击鼓进攻、鸣金收兵,这就是编码。把要传达给士兵的命令对应为一定的其它形式,比如命令“进攻”,经过如此的信息传递:
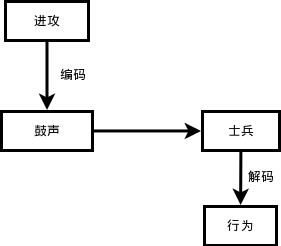
- 长官下达进攻命令,传令员将这个命令编码为鼓声(如果复杂点,是不是有几声鼓响,如何进攻呢?)。
- 鼓声在空气中传播,比传令员的嗓子吼出来的声音传播的更远,士兵听到后也不会引起歧义,一般不会有士兵把鼓声当做打呼噜的声音。这就是“进攻”命令被编码成鼓声之后的优势所在。
- 士兵听到鼓声,就是接收到信息之后,如果接受过训练或者有人告诉过他们,他们就知道这是让我进攻。这个过程就是解码。所以,编码方案要有两套。一套在信息发出者那里,另外一套在信息接受者这里。经过解码之后,士兵明白了,才行动。
以上过程比较简单。其实,真实的编码和解码过程,要复杂了。不过,原理都差不多的。
举一个似乎遥远,其实不久前人们都在使用的东西做例子:电报
电报是通信业务的一种,在19世纪初发明,是最早使用电进行通信的方法。电报大为加快了消息的流通,是工业社会的其中一项重要发明。早期的电报只能在陆地上通讯,后来使用了海底电缆,开展了越洋服务。到了20世纪初,开始使用无线电拨发电报,电报业务基本上已能抵达地球上大部份地区。电报主要是用作传递文字讯息,使用电报技术用作传送图片称为传真。
中国首条出现电报线路是1871年,由英国、俄国及丹麦敷设,从香港经上海至日本长崎的海底电缆。由于清政府的反对,电缆被禁止在上海登陆。后来丹麦公司不理清政府的禁令,将线路引至上海公共租界,并在6月3日起开始收发电报。至于首条自主敷设的线路,是由福建巡抚丁日昌在台湾所建,1877年10月完工,连接台南及高雄。1879年,北洋大臣李鸿章在天津、大沽及北塘之间架设电报线路,用作军事通讯。1880年,李鸿章奏准开办电报总局,由盛宣怀任总办。并在1881年12月开通天津至上海的电报服务。李鸿章説:“五年来,我国创设沿江沿海各省电线,总计一万多里,国家所费无多,巨款来自民间。当时正值法人挑衅,将帅报告军情,朝廷传达指示,均相机而动,无丝毫阻碍。中国自古用兵,从未如此神速。出使大臣往来问答,朝发夕至,相隔万里好似同居庭院。举设电报一举三得,既防止外敌侵略,又加强国防,亦有利于商务。”天津官电局于庚子遭乱全毁。1887年,台湾巡抚刘铭传敷设了福州至台湾的海底电缆,是中国首条海底电缆。1884年,北京电报开始建设,采用"安设双线,由通州展至京城,以一端引入署中,专递官信,以一端择地安置用便商民",同年8月5日,电报线路开始建设,所有电线杆一律漆成红色。8月22日,位于北京崇文门外大街西的喜鹊胡同的外城商用电报局开业。同年8月30日,位于崇文门内泡子和以西的吕公堂开局,专门收发官方电报。
为了传达汉字,电报部门准备由4位数字或3位罗马字构成的代码,即中文电码,采用发送前将汉字改写成电码发出,收电报后再将电码改写成汉字的方法。
注意了,这里出现了电报中用的“中文电码”,这就是一种编码,将汉字对应成阿拉伯数字,从而能够用电报发送汉字。
1873年,法国驻华人员威基杰参照《康熙字典》的部首排列方法,挑选了常用汉字6800多个,编成了第一部汉字电码本《电报新书》。
电报中的编码被称为摩尔斯电码,英文是Morse Code
摩尔斯电码(英语:Morse Code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。是由美国人萨缪尔·摩尔斯在1836年发明。
摩尔斯电码是一种早期的数字化通信形式,但是它不同于现代只使用0和1两种状态的二进制代码,它的代码包括五种:点(.)、划(-)、每个字符间短的停顿(在点和划之间的停顿)、每个词之间中等的停顿、以及句子之间长的停顿
看来电报员是一个技术活,不同长短的停顿都代表了不同意思。哦,对了,有一个老片子《永不消逝的电波》,看完之后保证你才知道,里面根本就没有讲电报是怎么编码的。
摩尔斯电码在海事通讯中被作为国际标准一直使用到1999年。1997年,当法国海军停止使用摩尔斯电码时,发送的最后一条消息是:“所有人注意,这是我们在永远沉寂之前最后的一声呐喊!”

我瞪着眼看了老长时间,这两行不是一样的吗?
不管这个了,总之,这就是编码。
计算机中的字符编码
先抄一段维基百科对字符编码的解释:
字符编码(英语:Character encoding)、字集码是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数串行、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
但计算机的字符编码,不是一蹴而就,而是有一个发展过程的。
ASCII码
计算机里采用二进制,这是毋庸置疑不用解释的了。
20世纪60年代,这是计算机发展的早期,那时候美国是很多领域的老大,计算机上也同样是老大,当然现在也还是老大,未来是不是就要看Chinese People了。老大就要做老大的事情,定规矩肯定是老大的事情,于是美国制定了一套字符编码,解决了英语字符与二进制位之间的对应关系,被称为ASCII码。
ASCII(pronunciation: 英语发音:/ˈæski/ ASS-kee[1],American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。由于万维网使得ASCII广为通用,直到2007年12月,逐渐被Unicode取代。
英语用128个符号编码就够了,但计算机不是仅仅用于英语。如果用来表示其他语言,128个符号是不够的。于是很多其它国家,都在ASCII码的基础上,搞了很多别的编码,比如汉语里面有了简体中文编码方式GB2312,使用两个字节表示一个汉字。
Unicode
编码方式上,各玩个的,就有点乱,于是就出现了“乱码”。比如电子邮件,发信人和收信人使用的编码方式不一样,收信人就只能看“乱码”了。
网络的发展,让地球都成为一个村了,同一个村里面就不能有很多“方言”,只能有一种,否则“乱了”。
于是Unicode)呼之出来了,看它的名字,你也知道,就是要统一符号的编码。
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为7.0.0,已收入超过十万个字符(第十万个字符在2005年获采纳)。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
但Unicode也不是完美的,存在一些问题。想了解哪些问题,请具体查阅参考文献:字符编码笔记:ASCII,Unicode和UTF-8
UTF-8
互联网催生了UTF-8。
Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)——UTF的含义。
UTF-8)是在互联网上使用最广的一种Unicode的实现方式。虽然它仅仅是Unicode的实现方式之一,但它真正一统江湖了。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码。
有UTF-8,言外之意还应该有UTF-n,n是一个别的数字。
的确如此,还有UTF-16等等,但UTF-8有很多优点,被广泛接受。
所以,以后,我们在Python的程序开发中,都要使用UTF-8编码。
注:参考文献:字符编码笔记:ASCII,Unicode和UTF-8
看完了一些关于编码的基本知识,再来看Python中的编码问题。
Python字符编码
Python编码容易让人迷茫,因为Python 2和Python 3还有区别。
如果你在Python 2中,在交互模式里按照下面的指令执行。
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
这说明Python 2的默认是ASCII编码。而Python 3,则不同。
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
所以,要注意是哪个版本。
之所以如此,根源是Python 2横空出世的时候,Unicode还没有来到这个世界。
在Python中,有两个内建函数,能够实现字符和对应数字之间的转换。
>>> ord("Q")
81
>>> chr(81)
'Q'
对于英文字母,不同版本的Python没有区别,但是,对于汉字就有区别了。
先看Python 2。如果你用Python 3,此段可以略过。
>>> ord("齐")
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
ord("齐")
TypeError: ord() expected a character, but string of length 2 found
Python 2默认是ASCII编码,齐这个字符已经超出了ASCII的范围,所以要报错。并且,从报错信息中可以看出更多信息。
>>> help(ord)
Help on built-in function ord in module __builtin__:
ord(...)
ord(c) -> integer
Return the integer ordinal of a one-character string.
Python 2中,要求ord()的参数所传递的是一个字符,即长度是1,而Python解释器现在认为齐这个汉字是两个字符的长度。
的确如此,汉字占据了两个字节。
>>> s = "齐"
>>> len(s)
2
>>> s
'\xc6\xeb'
再看Python 3,进行上述操作。
>>> ord("齐")
40784
>>> chr(40784)
'齐'
>>> help(ord)
Help on built-in function ord in module builtins:
ord(c, /)
Return the Unicode code point for a one-character string.
区别已经很明显了。
因此,Python 2做了扩展,使用一种新的方式,来声明那个字符串是Unicode编码。
>>> t = u'齐'
>>> len(t)
1
>>> t
u'\u9f50'
>>> ord(t)
40784
>>> type(t)
<type 'unicode'>
所以,使用Python 2的朋友们要注意了,在编程中,将字符串写成状如u'齐'是非常必要的,因为这样你使用的就是Unicode编码。
这样,貌似世界就和谐了。
真的吗?
encode和decode
因为种种原因,不可能世界上所有人都按照同一种模式生活,否则就不是“绚丽多彩”的世界了。
“绚丽多彩”的世界,就必须要encode和decode
- encode:编码
- decode:解码
字符串也有这样两个方法,分别负责编码和解码工作。
在Python 2中,它们分别是str.encode()和str.decode()。
>>> help(str.encode)
Help on method_descriptor:
encode(...)
S.encode([encoding[,errors]]) -> object
Encodes S using the codec registered for encoding. encoding defaults
to the default encoding. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that is able to handle UnicodeEncodeErrors.
>>> help(str.decode)
Help on method_descriptor:
decode(...)
S.decode([encoding[,errors]]) -> object
Decodes S using the codec registered for encoding. encoding defaults
to the default encoding. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeDecodeError. Other possible values are 'ignore' and 'replace'
as well as any other name registered with codecs.register_error that is
able to handle UnicodeDecodeErrors.
而在Python 3中,它是str.encode()。(细心的读者,有没有看到我叙述上的差别?)
>>> help(str.encode)
Help on method_descriptor:
encode(...)
S.encode(encoding='utf-8', errors='strict') -> bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
在两个版本中,是有却别的,恭请认真阅读文档信息。并且,在Python 3中不再提供str.decode()方法。想想也是合理的。因为Python 3中默认是UTF-8,就没有必要再解码成别的了吧,那不是要开历史的倒车吗?
所以,在Python 2中,你可以这么玩。
>>> a = "赵国"
>>> type(a)
<type 'str'>
>>> len(a)
4
>>> a
'\xd5\xd4\xb9\xfa'
这是一个基于ASCII得到的字节串,一个汉字两个字节。
>>> b = u'赵国'
>>> type(b)
<type 'unicode'>
>>> len(b)
2
>>> b
u'\u8d75\u56fd'
这是基于Unicode的字符串。两个术语:“字节串”和“字符串”,通过这个例子是否有了明晰?
>>> c = b.encode("utf-8")
>>> type(c)
<type 'str'>
>>> len(c)
6
>>> c
'\xe8\xb5\xb5\xe5\x9b\xbd'
这是其转化为UTF-8编码。请注意,以上三种不同编码下的长度,是不一样的。
>>> d = c.decode("utf-8")
>>> type(d)
<type 'unicode'>
>>> len(d)
2
>>> d
u'\u8d75\u56fd'
这样又变回去了。
这就是编码的转换方式。
关于编码问题,先到这里,点到为止吧。在编程实践中,如果有纠缠不清的问题,请尽情google,即可解决。
Python 2中如何避免中文是乱码
这个问题是一个具有很强操作性的问题。我这里有一个经验总结,分享一下,供参考:
首先,提倡使用utf-8编码方案,因为它跨平台不错。
经验一:在开头声明:
# -*- coding: utf-8 -*-
有朋友问我-*-有什么作用,那个就是为了好看,爱美之心人皆有,更何况程序员?当然,也可以写成:
# coding:utf-8
经验二:遇到字符(节)串,立刻转化为unicode,不要用str(),直接使用unicode()
unicode_str = unicode('中文', encoding='utf-8')
print unicode_str.encode('utf-8')
经验三:如果对文件操作,打开文件的时候,最好用codecs.open,替代open(这个后面会讲到,先放在这里)
import codecs
codecs.open('filename', encoding='utf8')
经验四:声明字符串直接加u,声明的字符串就是unicode编码的字符串
a = u"中"
我还收集了网上的一片文章,也挺好的,推荐给看官:Python2.x的中文显示方法
至于Python 3,因为天生就是UTF-8,所以对中文友好的。
关于字符串差不多要告一段落了。但是,Python的对象类型,还要继续。接下来“苦力”即将登场。
如果你认为有必要打赏我,请通过支付宝:qiwsir@126.com,不胜感激。